
Basic structure
The EDIFACT format starts with the definition of the special characters,has an structure for grouping messages and a very compressed way to
represent the elements of an segment.
UNA
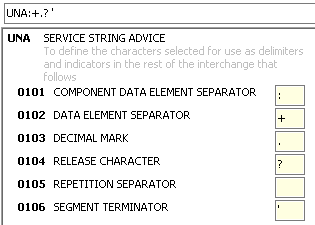
|
The optional UNA Segment is at the beginning of an interchange and defines the special characters that are used for the communication. When this segment is not given the characters below are used as an default. These elements are separated by the "Data Element Separator" for data-elements or by the "Component Data Element Separator" for composites. A composite has multiple data-elements. This is an easy way to couple multiple data-elements. Instead of using multiple times the three data-elements 2005,2380 and 2379 the composite C507 is used which includes all 3 data-elements. The "decimal mark" defines the character for the decimal-point. The "repetition separator" defines the character for "space". When you need to use one of the UNA-character you first have to escape this character with the "release character". E.G when you want to enter the following text "3+4=7" it would be interpreted as two data-elements "3" and "4=7" because "+" is the "data element separater". When you use "3?+4=7" the plus-character would not be interpreted as an separator, because "?" is the "release character". |
Structure
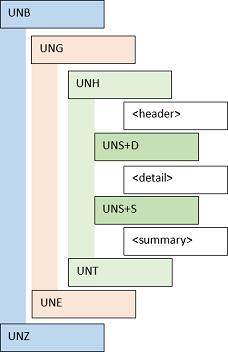 |
An EDIFACT interchanges starts with the UNB segment and ends with the UNZ segment. It is possible to group the messages of an interchange with the UNG and UNE segments. A message starts with a UNH and ends with a UNE segment. The message itself could have an header, detail and a summary, which are separated by an UNS segment. |
Message
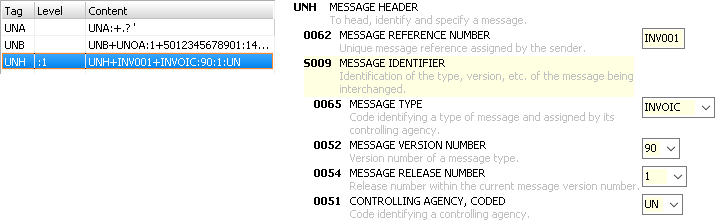
The UNH segments defines the used type and version of the message. Here an example message for business bills.
It is the message "INVOIC" for the year 1990 with release 1. Two times a year a new release is published by the UN.
Every new version could have new elements or remove old one. Therefore the validation of the message depends not only
on the message but also on the release that is used.
The picture above shows the message type "INVOIC" of the year 90 with release 1:
hierarchical structure of the segments
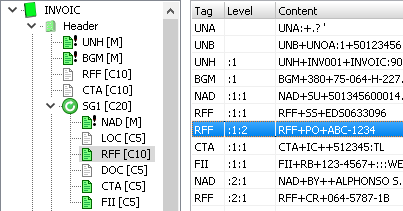
|
A message is a hierarchical structure of segments. Every level starts with an segment group that contains the single segments. A segment group and a segment could appear multiple times but could also be optional or mandatory. The following example shows the segment "RFF". It is optional and could be repeated 10 times [C10]. The example has two "RFF" segments. It is within the segment group "SG1", which is also optional and can be repeated 20 times [C20]. But every "SG1" segment group must have at least one "NAD" segment [M], because it is mandatory. The example show an address for the supplier [NAD+SU] and for the Buyer [NAD+BY]. The group for the supplier has the segments NAD-RFF-RFF-CTA-FII the buyer has the segments NAD-RFF only. |
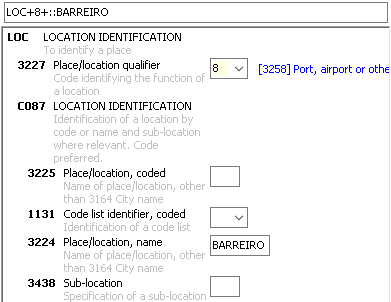
Data elements and composites of a segments.
|
A segment contains data elements and/or composites. The example below shows the segment "LOC", that consists of the data element 3227 and a composite C087. The composite has the elements 3225,1131,3224 and 3438. For the separation of the data elements the character "+" is used. Within a composite the ":" character is used as an separator. It is intended to use shortcuts when possible. This means that you can use an "+" to over skip multiple data-elements on a composite. |